LLM and Vector Databases
The Perfect Match
Vector databases can complement generative AI models, by providing an external knowledge base.

LLMs can only inspect a few thousand words at a time so if you have large documents how can the model find the most suitable information in all of those documents?
The answer: embeddings and vector stores
Embeddings encode all types of data (images, audio, text) into vectors that capture the meaning and context.
“Embedding allows you to build everything from search engines to recommendation systems to chatbots and a whole lot more…” Dale Markowitz
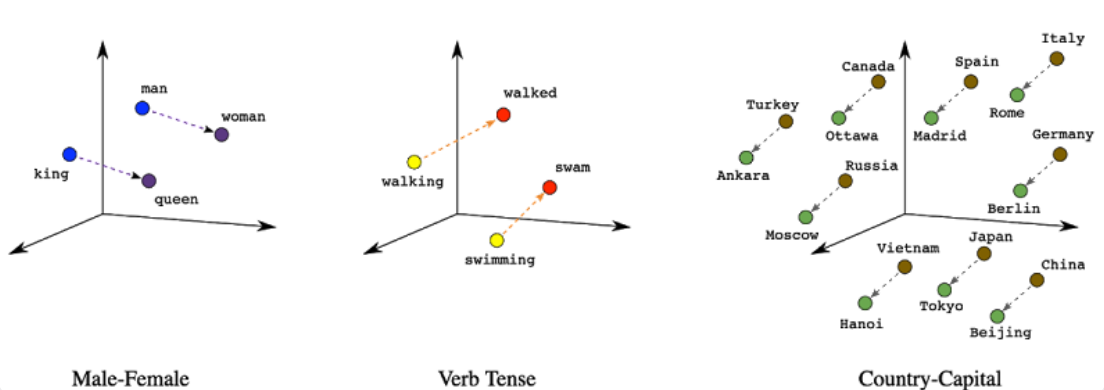
In the context of Large Language Models embeddings are vector representations of words or tokens in a text corpus. For GPT-3, embeddings play a crucial role in representing the input text and enabling the model to understand and generate coherent and contextually relevant responses.

The main ideas:
- Embedding vector captures content/meaning
- Text with similar content will have similar vectors
From a technical point of view what happens is that the data is stored into documents which will be sliced into chunks that will be stored as embeddings in a Vector Database or Vector Store. For each chunk, we create an embedding and store it in the Vector Store, and this is what happens when we create an index.
A Vector Store takes care of storing embedded data and performing vector searches for you.

When a query comes the model creates an embedding for that query, that will be compared with all the vectors in the database, in order to pick the n most similar (also known as similarity search).
For example, using langchain in-memory Vector Store and Open AI embeddings endpoint I’ve managed to embed a small amount of documents that enabled the model to provide a pinpoint response (for this particular domain knowledge).

So for the same prompt, we can clearly see the difference between a vanilla completion provided by OpenAI ChatGPT and an enhanced version using embeddings and Vector Store.
This is just the tip of the iceberg, for a more powerful solution, there are Vector Databases e.g.: Weaviate or Pinecone, which can be consumed as a fully-managed service.
Alternatives
Last but not least an alternative to Vector Database is to fine-tune the model, by providing a set of training examples that each consist of a single input (“prompt”) and its associated output (“completion”).
One important note, fine-tuning is not about teaching the model new information is about transfer learning in which the model learns new tasks, and by task, I mean reusing information that already has. Finetuning is more difficult than prompt engineering.
